声明:
本文由作者用心整理,希望对您有所帮助。如果您入门或困扰于该问题,请您静下心来阅读,准备纸笔推导,一定会有所收获。所有例子和引证均带有来源,可点超链接深入了解。
概述
拉格朗日松弛是一种求解整数规划的、基于优化的启发式算法。该算法能提供较为优质的解,可证明解的质量(可得到优化上下界),但不保证最优性。拉格朗日松弛的应用十分广泛,例如无容量限制的设施选址问题(该问题为NP-hard问题)。
拉格朗日松弛算法可追溯到Everett 1963年,Fisher 1973使用了该算法求解了调度问题。注意,该算法并不是拉格朗日提出的,是借鉴了拉格朗日乘子法的一些启示,由(Geoffrion 1974)命名。
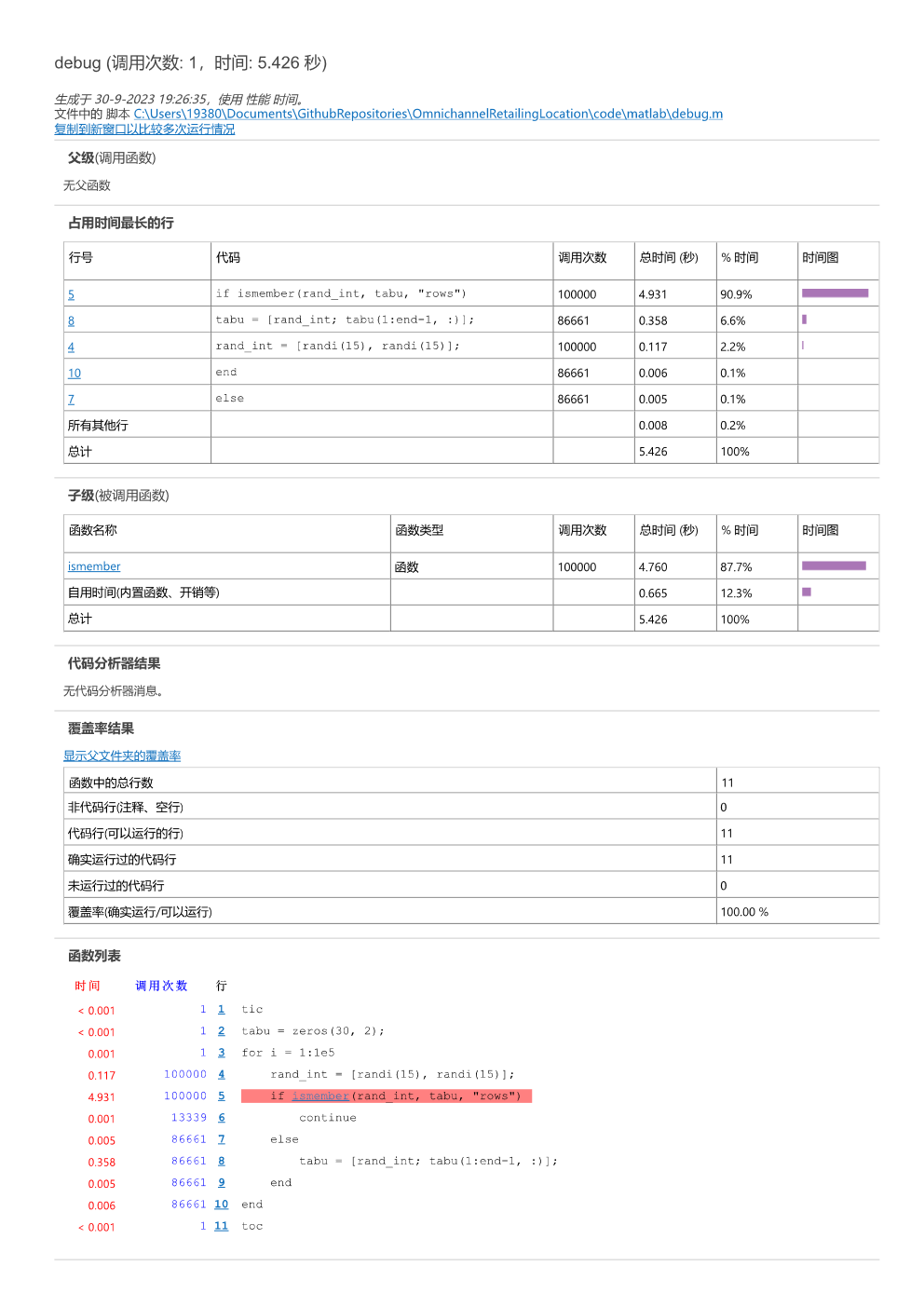
-
松弛方法对于一个优化问题十分重要,因为这种方法为最优值提供了“上下界限”。
-
松弛就是把一个问题的约束变弱,这样可行域就大了,也能方便求解了。
-
最小化问题中,松弛问题的最优值是下界。最大化问题是上界。
-
松弛技术的精髓就是设计一个容易求解的松弛问题并得到一个优质的“界”。
链接: Everett 1963
链接: Fisher 1973
从拉格朗日乘子法开始
微积分中,一类问题是求解一个函数的极大值或者极小值。当这个函数受限于另一个函数的时候,问题求解将变得困难。详见同济版《高等数学 下》(高等教育出版社)多元函数的极值及其求法——条件极值 拉格朗日乘数法。
维基百科的一个例子
参见维基百科。
求函数f(x,y)的极值,且要求满足条件g(x,y)=c。
这里简单描述一下原理和证明过程,详细证明参见引用来源。假设f(x,y)的取值为dn,注意dn是随x和y的值变化的。只有f(x,y)=dn和g(x,y)=c相切时,同时沿着有f(x,y)=dn和g(x,y)=c的方向前进,在这种情况下,会出现极值。
由于二者是相切关系,那么二者的梯度满足如下关系:(切线、法线、梯度的关系)
∇f(x,y)=−λ∇(g(x,y)−c)
于是,有
∇[f(x,y)+λ(g(x,y)−c)]=0
这样,如果求出了λ的值,带到F(x,y,λ)=f(x,y)+λ(g(x,y)−c)中,就能求出无约束条件下的极值和对应的极值点。F(x,y,λ)和f(x,y)在极值点处相等。极值点处,∇F(x,y,λ)=0,且∂λ∂F=g(x,y)−c,g(x,y)−c=0,所以极值点处有F(x,y,λ)=f(x,y)。
同济版第7版《高等数学 下》的例子
第九章p117给出了更详细的证明,这里直接给出结论:要找z=f(x,y)在附加条件ϕ(x,y)=0下的可能极值点,可做拉格朗日函数:
L(x,y)=f(x,y)+λϕ(x,y)
其中λ为参数,然后求L对x,y,λ的一阶偏导,并令其为0,将这个三个等式联立。方程组求解得到的解(x,y)就是f(x,y)可能的极值点。
整数规划拉格朗日松弛
问题构建
给定一个待求解的整数规划问题(P):
Z= s.t. mincxAx=bDx≤ex≥0 and integral (P)
我们松弛其整数约束,得到LP问题:
Z= s.t. mincxAx=bDx≤ex≥0(LP)
我们松弛第一个等于约束,得到一个松弛后的拉格朗日问题(LRu),其中u={u1,u2,...um}是拉格朗日乘子。
ZD(u)= s.t. mincx+u(Ax−b)Dx≤ex≥0 and integral (LRu)
设x∗是P问题的最优解,此时,有:
ZD(u)=mincx+u(Ax−b)≤cx∗+u(Ax∗−b)=cx∗=Z
这说明,ZD(u)的值一定小于等于Z的值。不等号的来源是松弛,因为LRu比P的约束更少,所以LRu的最优解一定小于等于把x∗直接带入LRu得到的目标函数值。由于在P中,Ax∗=b,所以cx∗+u(Ax∗−b)=cx∗=Z。
如果Ax=b的约束变成了Ax≤b,则需要求u≥0,如果Ax=b的约束变成了Ax≥b,则需要求u≤0。
总之,不管怎么样,ZD(u)≤Z在一定条件下成立,即ZD(u)小于等于原问题的最优目标函数值。
乘子u取值
拉格朗日对偶问题D
首先,应明确在u的特定取值下,ZD(u)可以等于Z。此时,这个问题就变成了跟u相关的问题。如何给u取值,使得ZD(u)尽可能取最大值以接近Z的问题,称作拉格朗日对偶问题D,即:
ZD=umaxZD(u)(D)
该问题的决策变量是u,目标函数是最大化ZD(u)的值。也就是说,求解原问题P的最小化目标函数值Z已经转换成求解拉格朗日对偶问题D的目标函数值ZD(u)了。
那么问题来了,拉格朗日对偶问题的形式很抽象,我们如何具象描述它呢?
拉格朗日对偶重构问题Dˉ
假设拉格朗日松弛LRu的可行解集X={x∣Dx≤e,x≥0 and integer}是有限集,则我们可以令X={xt,t=1,...,T}。
这样,问题D可重构为Dˉ:
ZDs.t.w=maxw≤cxt+u(Axt−b),t=1,...,T(Dˉ)
问:为什么可以这样重构?
*答:令w=ZD(u),问题D想求ZD(u)关于u的最大值,所以Dˉ的目标函数是求最大值。ZD(u)是最小化cx+u(Ax−b),那么ZD(u)一定小于等于LRu的任意一个可行解xt带入该表达式的值,即
mincx+u(Ax−b)=ZD(u)=w≤cxt+u(Axt−b)
当xt是LRu问题的最优解时等号成立。*
拉格朗日对偶重构问题的线性规划对偶Pˉ
这时,再求Dˉ的线性规划对偶Pˉ
ZD= s.t. mint=1∑Tλtcxtt=1∑TλtAxt=bt=1∑Tλt=1λt≥0,t=1,…,T(Pˉ)
对偶推导:从Pˉ向Dˉ推导,把b分解成凸组合;从Dˉ向Pˉ推导,把w看成1w+0u,其中w和u是无约束的决策变量。
虽然Pˉ和LP不是等价问题,即Pˉ并不是原问题P的线性松弛版本,但是当λt是整数(0或1)时,Pˉ等价于P。理由如下:xt是LRu的可行解,一定满足约束Dx≤e。既然满足了这个约束,在所有的可行解中,也肯定存在一个xt满足Axt=b,那么令对应的λt等于1即可。(满足条件a的所有解中,一定有一个解同时满足a和b,子集关系)
拉格朗日对偶重构问题Dˉ的意义
问题Dˉ表明,ZD(u)是一系列线性函数的下限值。为了方便理解,假设x的变量数只有一个,T=4表示对于问题LRu仅有4个可行解。那么,ZD(u)随u变化的图像如图所示:
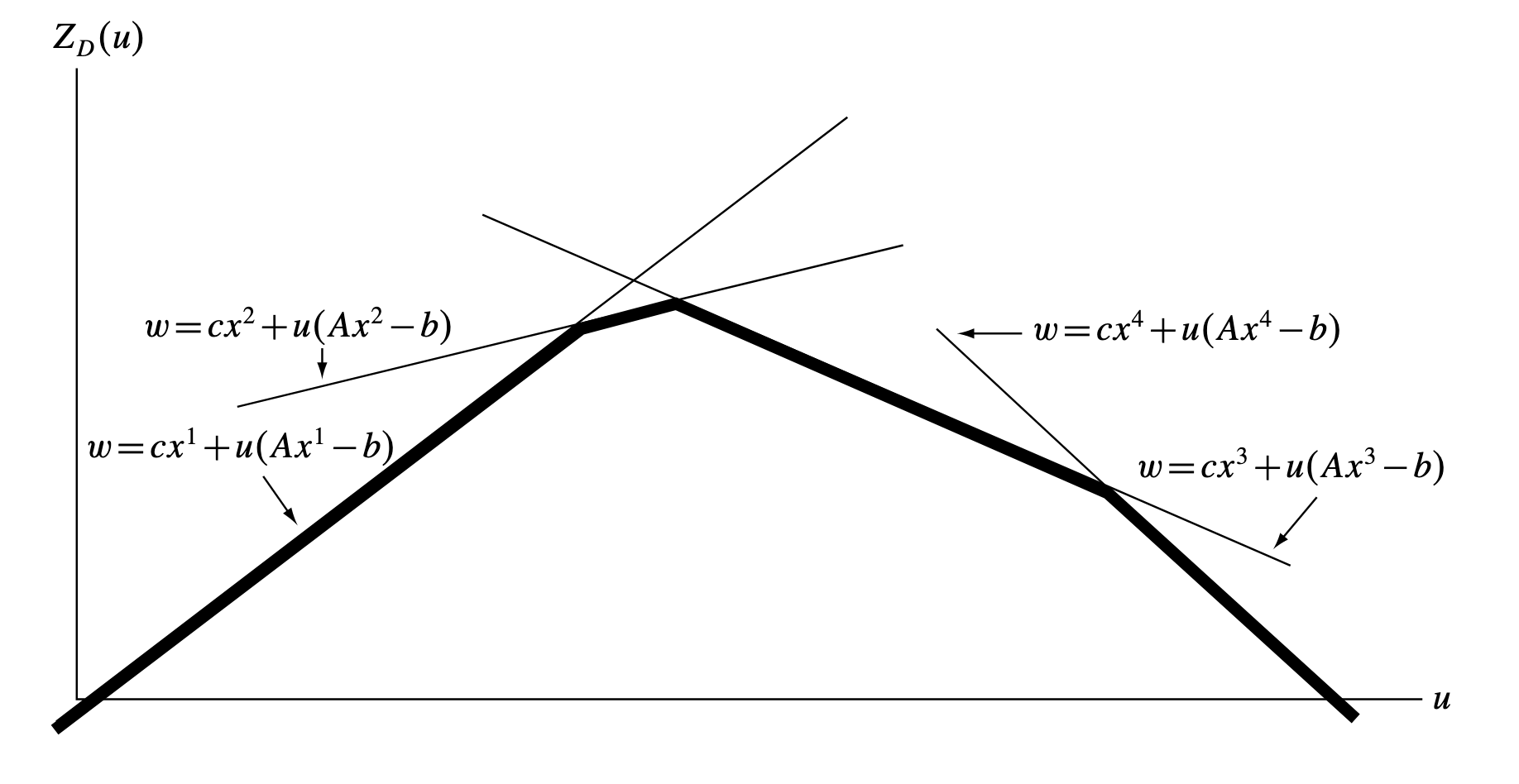
在这个图中,xt是已知的,是常数,那么得到了四个关于u的线性函数。取这些函数在u不同取值的最小值,即为函数ZD(u),如图中加粗线条所示。
我们发现,ZD(u)是连续的,是凹函数(参照国际定义)。这样找最大值就很简单,比如,我们使用爬山算法,但是我们不能求导,因为最优点处不可导。
既然不可导,那就用次梯度法。
次梯度法
次梯度概念
满足如下公式的 y 值为 ZD(u) 在 uˉ 处的次梯度。
y(u−uˉ)≥ZD(u)−ZD(u),∀u
次梯度性质
- 向量Axt−b在xt求解 LRu 对应位置的次梯度。其余的次梯度都是这些“基础”次梯度的凸组合。
- 当且仅当u∗和λ∗是可行的且满足互补松弛定理时,u∗是Dˉ的最优解且λ∗是Pˉ的最优解,这等价于当且仅当ZD(u) 在 u∗ 处的次梯度为0时,u∗是D的最优解。(说白了就是ZD(u)取到了关于u的最大值)
次梯度法更新乘子
给定一个初始的乘子值 u0,后续乘子第k次迭代的值为uk,迭代公式如下:
uk+1=uk+tk(Axk−b)
其中xk是(LRuk)的最优解,tk是一个正数,称为迭代步长。
Goffin (1977)表明:
当tk→0且∑i=0kti=0时,ZD(uk)→ZD。
常用的迭代步长公式为:
tk=∣∣Axk−b∣∣2λk(Z∗−ZD(uk))
其中,λk是一个(0,2]之间的标量,Z∗是ZD的上界,且使用启发式修改为P的可行解。通常,λk的初始值设置为2,当一定迭代次数后,ZD(u)的值仍未增加,λk的值减半。
注意,这是一个经验性的方法,并不一定能满足最优收敛。
总结
上述的内容只是一个方法论,我们想求解一个问题,还是面临很多的困难的。具体的问题需要具体的分析,包含但不限于松弛哪个约束、获取上界的启发式方法、算法参数的调整等。具体的例子,可参考本人的硕士毕设(在github仓库中)使用拉格朗日松弛求解了一个选址问题。